Information Projects – “Encyclopedia” Type
The most familiar type of
crowdsourced project is the “encyclopedia” type, where a project provides a
structure and often editorial and other management toward creating a large
“anthology” work composed of public contributions. I will touch on some
examples, although I’ll discuss them quickly because so many of them are already
familiar.
Wikipedia is, of course, the
archetypal example of this. Another
example of this type of project is the recipe repository, of which there are
many online – RecipeSource is one of the oldest, while AllRecipes is one of the
most popular. There are also many sites that collect song lyrics contributed by
users, such as Lyrics.com. A crowdsourced project of special interest to
librarians is LibraryThing, which was originally designed as a tool for
cataloging a personal book collection, but has grown into a more
general-purpose database containing book information, demographics, historical
data on book collections of famous people, and more. Another important literary
project is Project Gutenberg, the oldest repository of e-texts in existence.
Since 1975, Project Gutenberg has coordinated public efforts to digitize and
archive public domain works and provide them free to the public. Project
Gutenberg also uses a sophisticated system of crowdsourced effort to proofread
its books, and an affiliated project, LibriVox, is working on creating and
archiving free audiobooks of public works produced by crowdsourced effort.
Some projects begin as a
different type of crowdsourcing project, but turn into an encyclopedia-type
project over time. Ask Metafilter began as a project to create a large
community that would answer any question asked; it was an outgrowth of a larger
community blog, MetaFilter, where members would post anything they thought
might interest other people. Over time, both sites have become a huge
searchable repository for answers to a staggering variety of questions ranging
from technical problems to personal quandaries to where to find other obscure
information. If you need a more focused way to crowdsource personal issues, WotWent Wrong offers a website and app that lets users anonymously upload the
details of romantic relationship breakups, so that other users can advise,
counsel, critique, and offer closure.
Research Projects – “Mosaic” Type
Much crowdsourced research is
based on the idea that lots of people will donate small bits of time or effort
to a cause, especially if it’s one they believe in and the task is fun, and
those small bits of work add up. Crowdsourcing really excels at doing work
that’s easy for humans, but hard for computers to do, such as image recognition
and metatagging, and natural language
recognition.
 |
| A sample FoldIt puzzle |
One very effective crowdsourced
research project is FoldIt. Understanding the structure of proteins and how
they can fold is a key scientific problem in understanding many diseases and
finding cures for them, including HIV, Alzheimer’s Disease, and cancer. Solving
this problem has been one of biology’s toughest challenges, difficult and
expensive to research using computers. FoldIt enlists the help of users by
offering them a puzzle based on a protein folding problem. Humans can see
solutions to such a puzzle much more easily and faster than computers can, and
have fun doing it. FoldIt players have made great progress in adding to scientific
knowledge in this field, including solving the structure of a retrovirus enzyme
critical to developing anti-AIDS drugs in a matter of days, where it had
previously eluded scientists completely.
Another game project, Galaxy Zoo, enlists the
public in morphological classification of galaxies by asking them to look at
telescope photographs and identify galaxy types visually. Volunteers have
identified more than 70 million galaxies so far, most of which had never been
seen by human eyes before, since the photographs were taken and processed by
robotic cameras.
 A CAPTCHA is a website security
device that makes sure users are human and not virtual, to reduce spamming and
other malicious site interference. Almost everyone has seen the box where
you’re asked to re-type some letters before you can enter a site. reCAPTCHA is
a service that uses this effort, millions of times per day, to help identify
digitized text that can’t be read by optical character reader software. Words
that cannot be read correctly by OCR are given to users in conjunction with
another word for which the answer is already known. The user is then asked to
read both words. If they give the right answer for a known word, the system
assumes their answer is correct for the new one. The same word is given to many
users to verify the answer. Currently, the project is helping create digital
editions of older issues of the New York Times and books in the Google Books
project.
A CAPTCHA is a website security
device that makes sure users are human and not virtual, to reduce spamming and
other malicious site interference. Almost everyone has seen the box where
you’re asked to re-type some letters before you can enter a site. reCAPTCHA is
a service that uses this effort, millions of times per day, to help identify
digitized text that can’t be read by optical character reader software. Words
that cannot be read correctly by OCR are given to users in conjunction with
another word for which the answer is already known. The user is then asked to
read both words. If they give the right answer for a known word, the system
assumes their answer is correct for the new one. The same word is given to many
users to verify the answer. Currently, the project is helping create digital
editions of older issues of the New York Times and books in the Google Books
project.
Another project that uses
language recognition is What’s On the Menu, the New York Public Library’s
effort to make its historical menu collection into a searchable database. Users
who log in can help identify dishes, prices, meal organization, geographic
information, and more from scanned selections from the collection’s 45,000
menus. Eventually, this information will be available for historians, cultural
researchers, chefs, educators, and anyone else to make new connections and
discoveries, and learn more about our culinary past.
Project Implicit provides visual
tests that the public can take to measure implicit bias and attitudes. By
asking users to choose quickly between images and words onscreen, the Implicit
Association Test makes it possible to measure attitudes and beliefs that
people are either unwilling or unable to report, such as prejudices that may be
unconscious or embarrassing. The information provides interesting individual
feedback as well as valuable research information about public attitudes.
PatientsLikeMe was created in
2002 as a way to help accelerate learning on amyotropic lateral sclerosis, aka
Lou Gehrig’s disease. Now its 80,000 members share personal details of their
medical history with fellow members in a network that not only provides
support, but data that is aggregated to track patterns and responses to various
treatments. For rare diseases like ALS, many doctors may only encounter one or
two patients in their lifetime, but PatientsLikeMe allows them to compare and
review treatments with thousands of other patients, helping them quickly
understand options and determine an effective course of action.
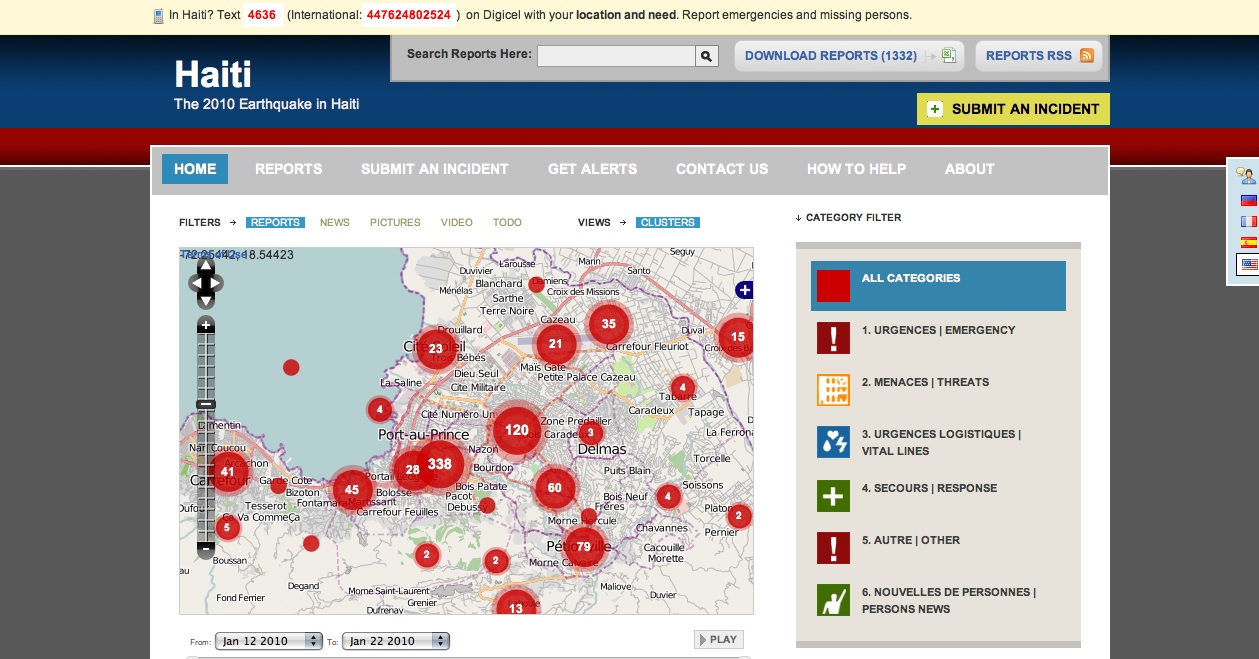
Often, crowdsourcing can respond
quickly in times of crisis or when other infrastructures have broken down.
Ushahidi is a company that provides
open-source software to enable collection, visualization, and dynamic mapping
of crowdsourced reporting of time-sensitive crisis information. It was
initially developed to map reports of violence in Kenya after the post-election
fallout at the beginning of 2008. The original website was used to map
incidents of violence and peace efforts throughout the country based on reports
submitted by 45,000 users via the web and mobile phone. Since then, Ushahidi
continues to develop and freely distribute its platform, apps, and services to help
coordinate social media and individual in-the-moment reporting of problems and
assistance routing for people dealing with situations like bombing in Mumbai
and the recent earthquakes in Japan and Haiti. Ushahidi is also being used by
human rights organizations to map incidents of violence, corruption, and other
issues of note that are often overlooked or suppressed in traditional media
reporting. Crowdsourcing can also help in the aftermath of a crisis – MapMill is currently enlisting the public to analyze aerial photos of places affected
by Hurricane Sandy, to help quickly identify and assess storm damage.
Marty, this is an incredible piece of research! I am truly amazed at the depth of your knowledge on this topic. It makes me proud to call you friend. I wish the best for you as you pursue this next phase of your life...
ReplyDeleteAnne Kim
Thanks, Anne! It really was fun to do. Crowdsourcing is really fascinating to me, and getting to really dig in and see so many forms was exhilarating, if slightly overwhelming. :->
ReplyDelete